Huffman Coding
Huffman encoding is a lossless compression greedy algorithm.
It basically assigns variable length codes to input characters making sure that the character with the highest frequency gets the smallest code length. The least frequented character gets the largest code.
Steps to build Huffman Tree
Input is array of unique characters along with their frequency of occurrences and output is Huffman Tree.
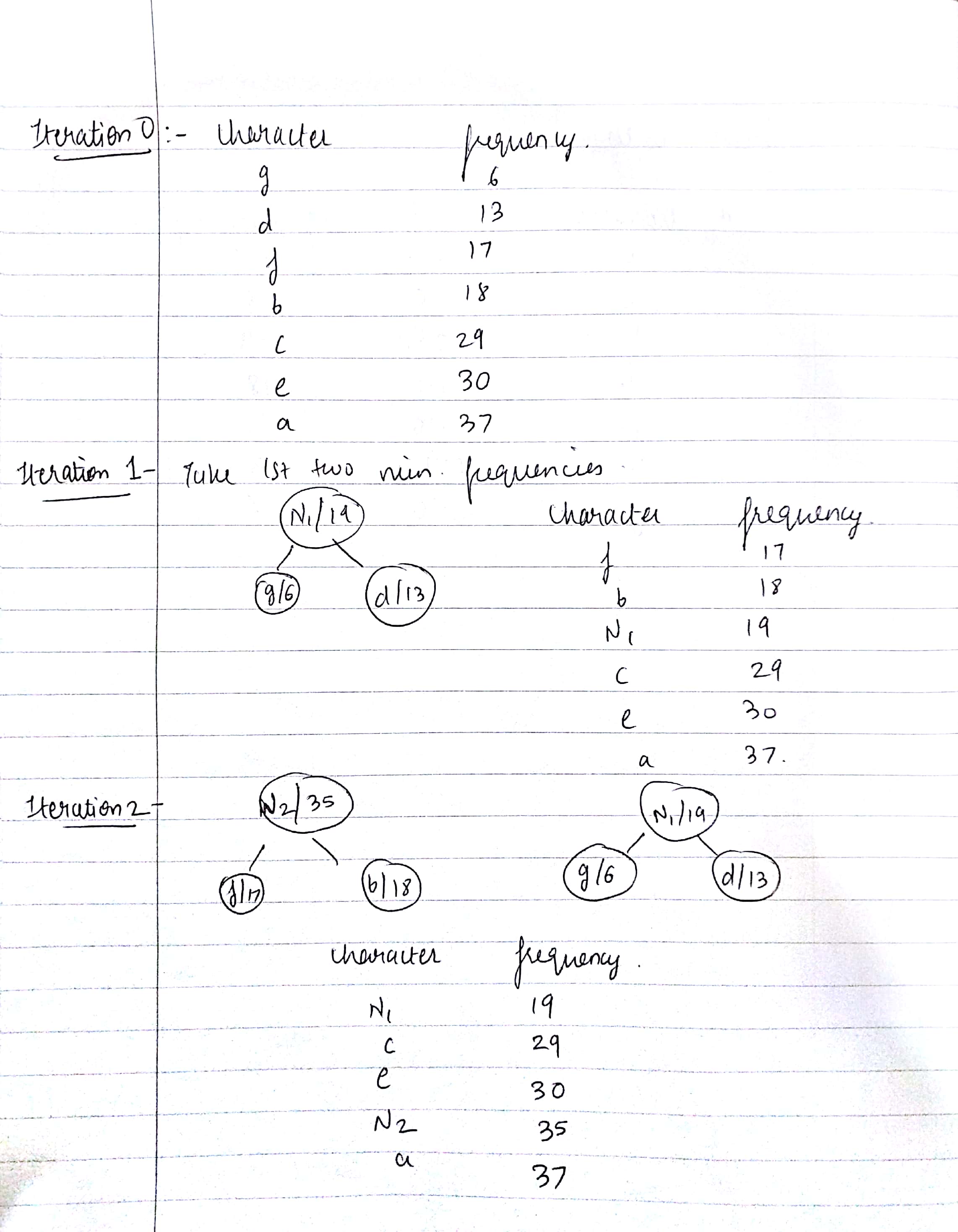
- Take all the uniques characters and create their leaf nodes. Build a min heap of all the leaf nodes.
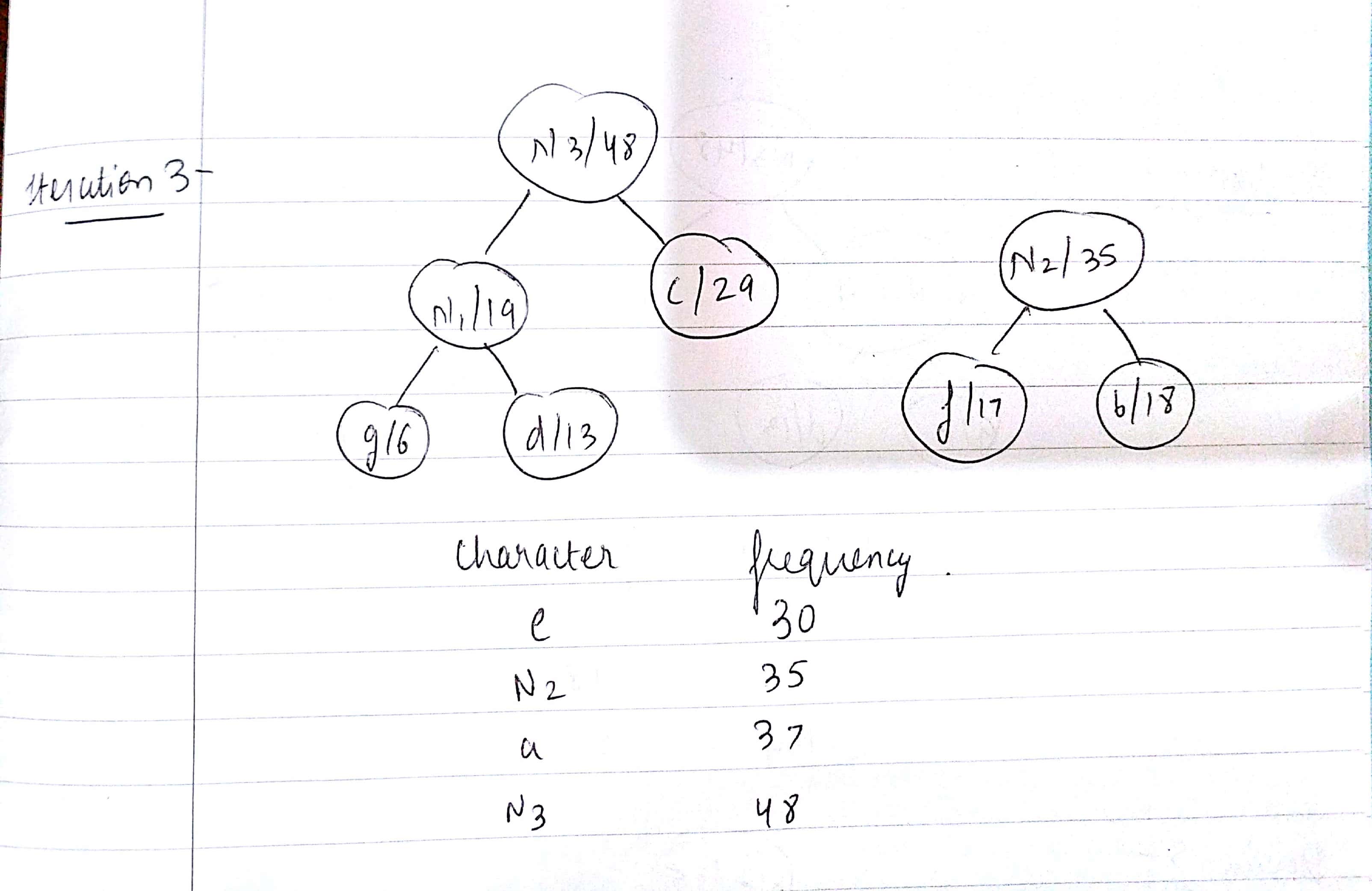
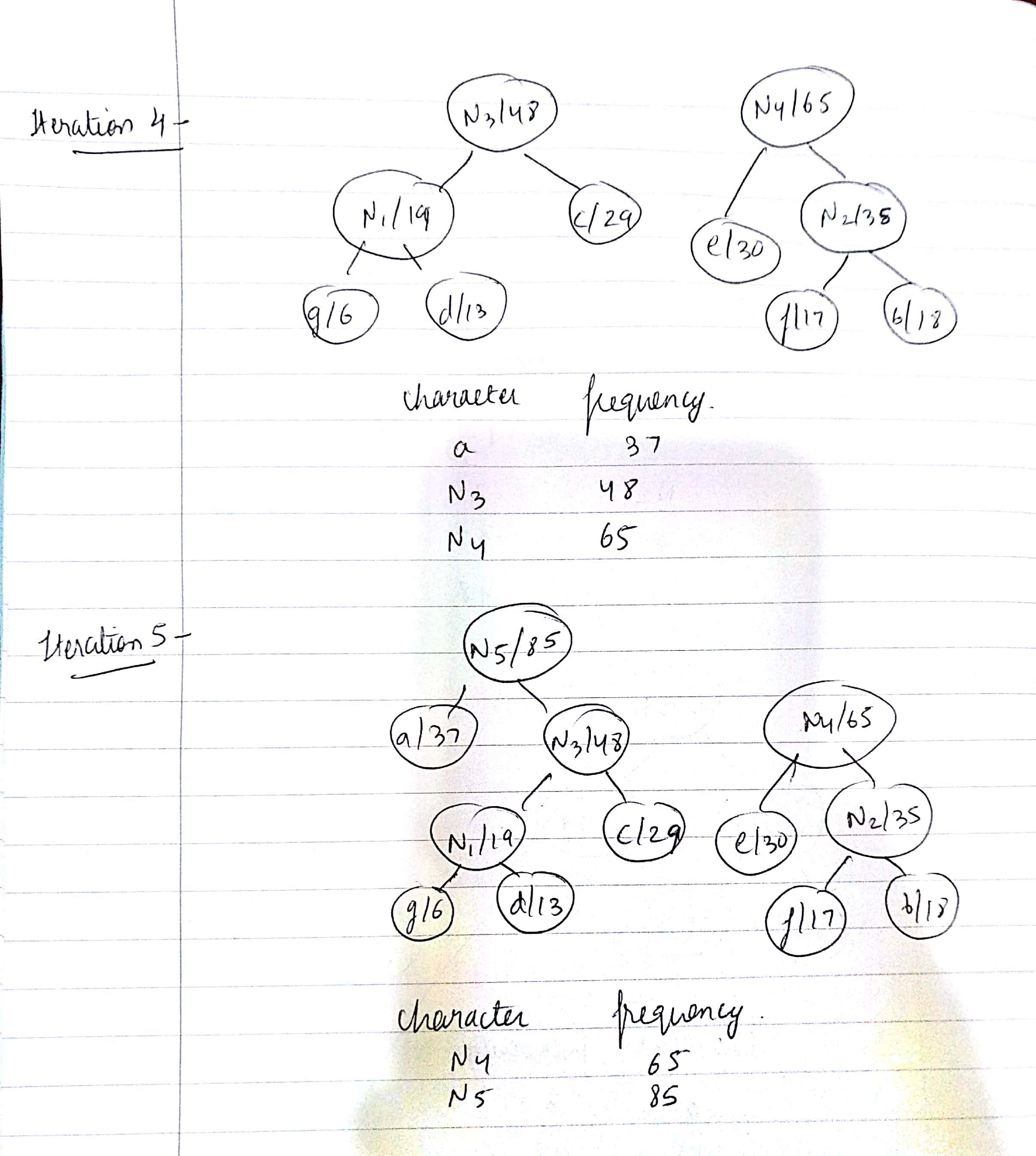
- Choose two nodes with the minimum frequency from the min heap.
- Construct a new internal node which is the sum of the frequencies of the two nodes we chose in the above step. Make the first extracted node as it's left child and the other one as its right child. Add this node to the min heap.
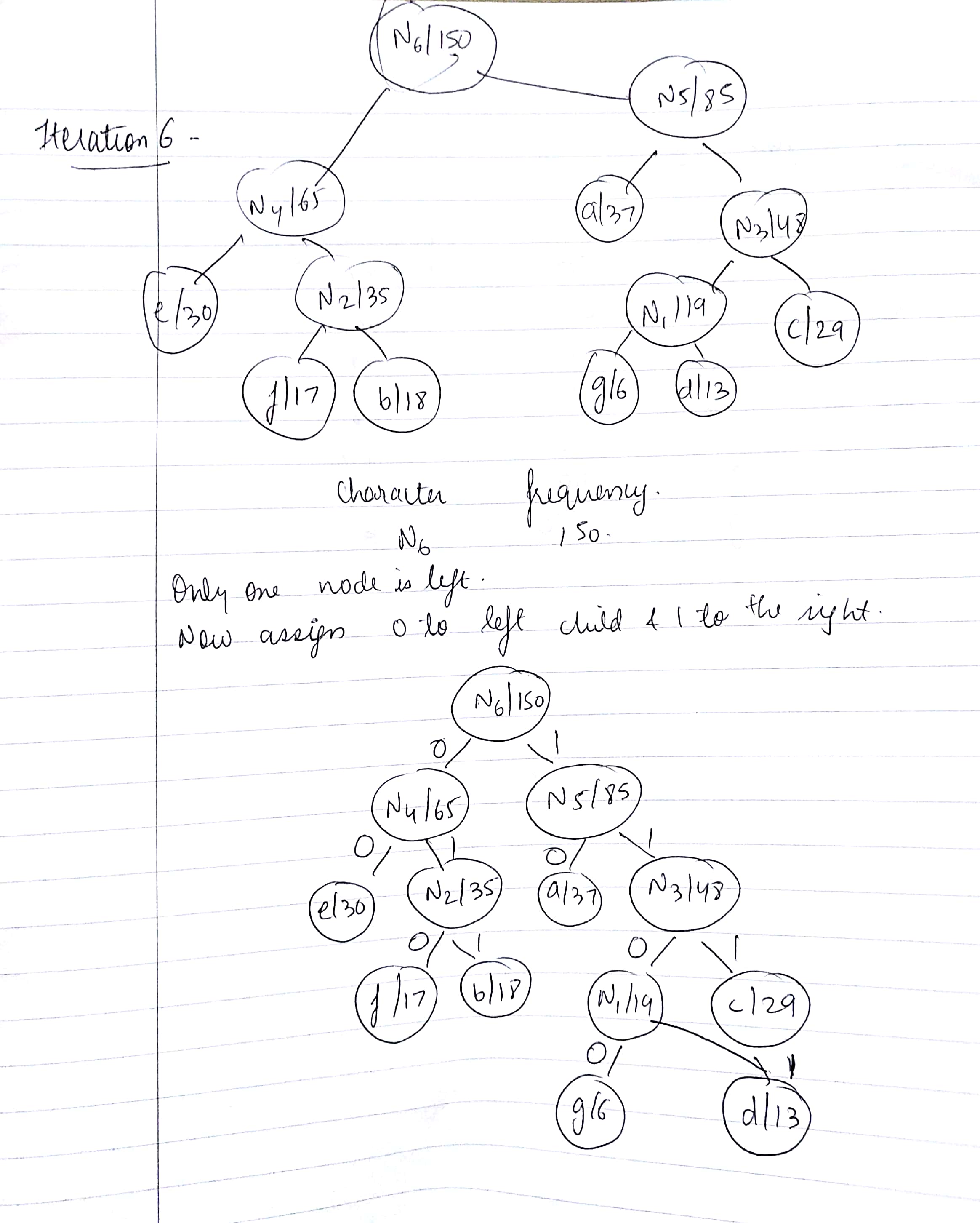
- Repeat steps 2 and 3 till the heap contains only one node. That will be the root node and the tree is complete.
- Finally, assign 0 to all the left edges of the tree and assign 1 to the right edges and we can get codes for each character by traversing through the tree.

_Time complexity:_O(nlogn) where n is the number of unique characters. If there are n nodes, extractMin() is called 2*(n – 1) times. extractMin() takes O(logn) time as it calles minHeapify(). So, overall complexity is O(nlogn).
If the input array is sorted, there exists a linear time algorithm. We will soon be discussing in our next post.